Fixing initial loss
Durante il primo training dei dati è possibile che il valore del loss, calcolato durante la prima iterazione, sia molto maggiore di quelli calcolati nelle successive iterazioni.
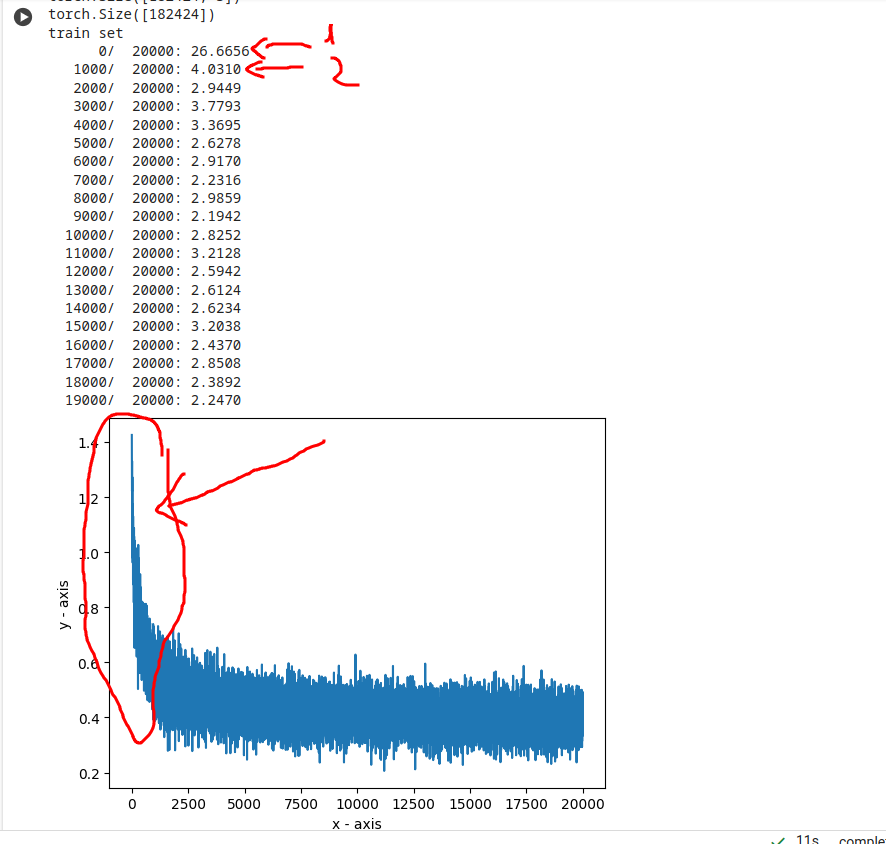
Nel grafico è mostrato l'andamento del log10(loss), si vede la classica forma a "mazza da hockey", con il valore del loss che nella prima iterazione è 26 (circa 1.4 nel caso del log10()), contro i circa 3 delle altre iterazioni.
E' bene riportare il valore del primo loss circa come gli altri.
Questo valore così alto è dovuto al fatto che, all'inizio, assegniamo valori random ai pesi e bias.
Sarebbe più giusto dare le stesse probabilità ai caratteri di output, almeno all'inizio.
Ogni carattere in output dovrebbe avere probabilità 1/27 = 0.37 circa del 4% o, comunque, per evitare valori del loss alti,
Considerando l'inizializzazione della rete, bisogna contenere l'entità dei logits in uscita, almeno per la prima interazione.
Per farlo possiamo settare il bias dell'output layer a 0 e rendere i valori dei pesi di quel layer contenuti.
Introduciamo dei moltiplicatori, in fase di inizializzazione:
# output layer
W2 = torch.randn((n_hidden, output_size), generator=g) * 0.01
b2 = torch.randn(output_size, generator=g) * 0