Tuning activation function
Abbiamo visto che una funzione di attivazione come tanh() può saturare facilmente, può
cioè produrre molti valori estremi -1 e +1:
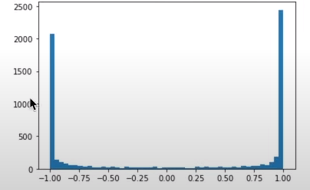
quando i valori di h dati in input a tanh() sono del tipo:
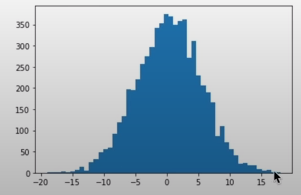
cioè creano una distribuzione molto larga.
Questa saturazione implica che i neuroni in questo stato vengono allenati meno, aggiornano di rado i loro pesi.
Proviamo a risolvere la saturazione.
# durante il forward pass:..
emb = C[Xb] # embed the characters into vectors
embcat = emb.view(emb.shape[0], -1) # embcat è una distribuzione gaussiana, non dà problemi
# il problema si crea qui, dalla moltipliczione con w1 e somma con b1,
# che influenzano embcat!
hpreact = embcat @ W1 + b1
# hpreact non dovrebbe avere valori molto lontani da zero!
# altrimenti avremo il problema della saturazione!
# quindi agendo su W1, b1 aggiungiamo i moltiplicatori:
W1 = torch.randn((n_embd * block_size, n_hidden), generator=g) * 0.2
b1 = torch.randn(n_hidden, generator=g) * 0.01
che causeranno un hpreact di forma meno estrema, per ottenere, poi:
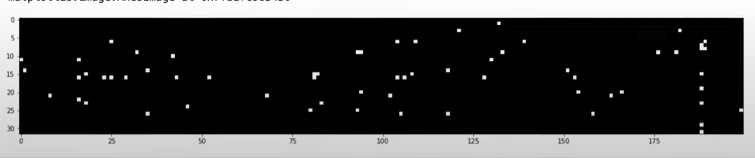
bassissime zone bianche, poca saturazione, scongiurando il problema dei dead neuron, non avendo alcuna colonna
interamente bianca.
boolean_tensor = hpreact.abs() > 0.99
plt.figure(figsize=(20, 10))
plt.imshow(boolean_tensor, cmap="gray", interpolation="nearest")