Embedding vector scaling
Consideriamo l'esempio dei 27 caratteri dell'alfabeto embeddati in uno spazio a 2 dimensioni x, y,
in una lookup table.
Creiamo un grafico con:
# visualize dimensions 0 and 1 of the embedding matrix C for all characters
plt.figure(figsize=(8,8))
plt.scatter(C[:,0].data, C[:,1].data, s=200)
for i in range(C.shape[0]):
plt.text(C[i,0].item(), C[i,1].item(), itos[i], ha="center", va="center", color='white')
plt.grid('minor')
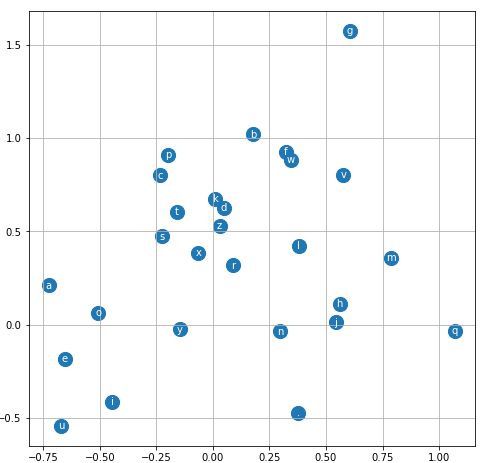
Per aumentare le dimensioni della lookup table, es da 2 a 10, facciamo, partendo dalla definizione della lookup table a 2 dimensioni:
g = torch.Generator().manual_seed(2147483647)
# parametri di input (27 caratteri embeddati in 2 dimensioni)
C = torch.randn((27, 2), generator=g)
# hidden layer composto da 300 neuroni, ogni neurone accetta tutti gli input
# dai neuroni dell'input layer, che in totale sono 6 (3 caratteri per 2 dimensioni)
W1 = torch.randn((6, 300), generator=g)
b1 = torch.randn(300, generator=g)
# output layer composto da 27 neuroni, ogni neurone ha 300 input, corrispondenti
# alle uscite dell'hidden layer
W2 = torch.randn((300, 27), generator=g)
b2 = torch.randn(27, generator=g)
parameters = [C, W1, b1, W2, b2]
aumentiamo a 10 dimensioni:
g = torch.Generator().manual_seed(2147483647)
# parametri di input (27 caratteri embeddati in 10 dimensioni)
C = torch.randn((27, 10), generator=g)
# hidden layer composto da 300 neuroni, ogni neurone accetta tutti gli input
# dai neuroni dell'input layer, che in totale sono 30 (3 caratteri per 10 dimensioni)
W1 = torch.randn((30, 300), generator=g)
b1 = torch.randn(300, generator=g)
# output layer composto da 27 neuroni, ogni neurone ha 100 input, corrispondenti
# alle uscite dell'hidden layer
W2 = torch.randn((300, 27), generator=g)
b2 = torch.randn(27, generator=g)
abbiamo modificato soltanto la dimensione di C e quella dei pesi W1, che prendono in ingresso gli output dell'input layer
Bisogna ricordarsi di CAMBIARE anche nel forward pass:
da:
for _ in range(epoch): # epoch
...
...
# 1) forward pass
emb = C[X] # (32,6)
h = torch.tanh(emb.view(32, 6) @ W1 + b1) # (32, 300)
a:
for _ in range(epoch): # epoch
...
...
# 1) forward pass
emb = C[X] # (32,30)
h = torch.tanh(emb.view(32, 30) @ W1 + b1) # (32, 200)