Evaluation
Evaluation of a fine tuned model by humans
Simple human evaluation of a fine tuned model
Now that we have a fine tuned model we need to evaluate it, to test if it’s better than the original model.
Evaluation process
We want compare the performance of the fine tuned model (Llama-3.2-3B-Instruct LoRA) with the original model (Llama-3.2-3B-Instruct) in the task of form filling.
A simple way to evaluate the model is to ask a human to check visually if the model is better than the original model.
So, to do this in a systematic way, we can use a list of models outputs for the same user prompts to evaluate the model.
Starting from our synthetic dataset, created by ChatGPT 3.5 Turbo, used to train the LoRA model, we can create a csv file containing the following columns:
1) from synthetic dataset:
system_prompt: Contains the instructions that are given to the model. It defines the fields to be extracted.user_prompt: Contains the user’s text from which the information should be extracted.expected_completion: This is the “ground truth” - the ideal output we expect from the model as created by ChatGPT 3.5 Turbo.
2) from base model inference:
base_result: The output generated by the original base model (in this specific case: Llama-3.2-3B-Instruct).
3) from fine tuned (LoRA) model inference:
lora_result: The output from our new, fine-tuned model (in this specific case: Llama-3.2-3B-Instruct LoRA).
This allows for a side-by-side comparison between the base model and the fine-tuned model against the expected outcome.
Creating the csv file
We have a lot of objects with different texts but same structure, in our synthetic dataset:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
prompts = [{
"system_prompt": {
"role": "system",
"content": "\nEach response line matches the following format:\nFIELD identifier^^^value\n\nGive a response with the following lines only, with values inferred from USER_DATA:\n\nFIELD address^^^The address of type string\nFIELD property_type^^^The property_type of type string\nFIELD size^^^The size of type integer\nFIELD kitchen^^^The kitchen of type boolean\nFIELD bathroom_window^^^The bathroom_window of type boolean\nFIELD floor^^^The floor of type integer\nFIELD elevator^^^The elevator of type boolean\nEND_RESPONSE\n\nDo not explain how the values were determined.\nFor fields without any corresponding information in USER_DATA, use value NO_DATA.\n"
},
"user_prompt": {
"role": "user",
"content": "\nUSER_DATA:La casa in affitto si trova in Via Roma, 12. E' un monolocale di 40 metri quadrati con cucina a vista e bagno finestrato. E' situato al secondo piano di un edificio con ascensore.\n"
},
"expected_completion": {
"role": "assistant",
"content": "FIELD address^^^Via Roma, 12\nFIELD property_type^^^monolocale\nFIELD size^^^40\nFIELD kitchen^^^True\nFIELD bathroom_window^^^True\nFIELD floor^^^2\nFIELD elevator^^^True\n"
}
}, {
...
}, ...]
We need to create a script to run inference from the prompts for base and fine tuned models and then save the results in a csv file.
Can implement a run_model() function to do this.
It takes a series of prompts, each with a system message and user input, and sets up a transformers library pipeline for text-generation, configured for inference.
Then it iterates through the prompts, feeding them to the model and collecting the generated responses.
The final output is a list of the model’s text replies.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
def run_model(prompts, model, tokenizer, limit=None):
"""
Generate text completions for a list of prompts using the provided model.
Args:
prompts (list): List of dicts with 'system_prompt' and 'user_prompt' keys
model: Hugging Face model instance
tokenizer: Hugging Face tokenizer instance
limit (int, optional): Max number of prompts to process
Returns:
list: Generated assistant responses (strings with normalized newlines)
"""
results = []
# Create text generation pipeline with optimized settings for inference
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
torch_dtype=torch.bfloat16, # Use half precision for memory efficiency
device_map="auto", # Automatically distribute model across available devices
)
for line_num, prompt in enumerate(prompts):
if limit and line_num > int(limit):
break
messages = [
prompt['system_prompt'],
prompt['user_prompt']
]
outputs = pipe(
messages,
max_new_tokens=300
)
assistant_response = outputs[0]["generated_text"][-1]['content'].replace('\n\n', '\n')
results.append(assistant_response)
return results
Now we can create a script to run the inference and create the csv file. This script orchestrates the comparison between a base model and its fine-tuned version.
Using the run_model() function, it generates responses from both models (base and fine tuned) for a list of prompts. Finally, it compiles the results into a single CSV file. Each row of the CSV contains the original prompt, the expected output, and the actual outputs from both the base and the fine-tuned models, allowing for easy side-by-side comparison.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
# 3B model
BASE_MODEL = "meta-llama/Llama-3.2-3B-Instruct"
LORA_DIR = "/outputs/lora-out/checkpoint-764" # fine tuned model at certain checkpoint
# models inference
#firstly we use base model inference
base_model = AutoModelForCausalLM.from_pretrained(BASE_MODEL, device_map="auto")
tokenizer = AutoTokenizer.from_pretrained(BASE_MODEL)
base_results = run_model(prompts, base_model, tokenizer, limit)
# then we use fine tuned model:
# Load the LoRA weights and merge them with the base model:
lora_model = PeftModel.from_pretrained(base_model, LORA_DIR)
lora_model = lora_model.merge_and_unload()
lora_results = run_model(prompts, lora_model, tokenizer, limit)
# now we can create the csv file:
with open("output_file.csv", 'w', newline='', encoding='utf-8') as csvfile:
csvwriter = csv.writer(csvfile)
csvwriter.writerow(['system_prompt', 'user_prompt', 'expected_completion', 'base_result', 'lora_result'])
for prompt, base_result, lora_result in zip(prompts, base_results, lora_results):
csvwriter.writerow([
prompt['system_prompt']['content'],
prompt['user_prompt']['content'],
prompt['expected_completion']['content'],
base_result,
lora_result
])
It produces a csv file like this, so a human can view the results and the differences between the models inference responses to decide if the fine tuned model is acceptably better than the base model or not.
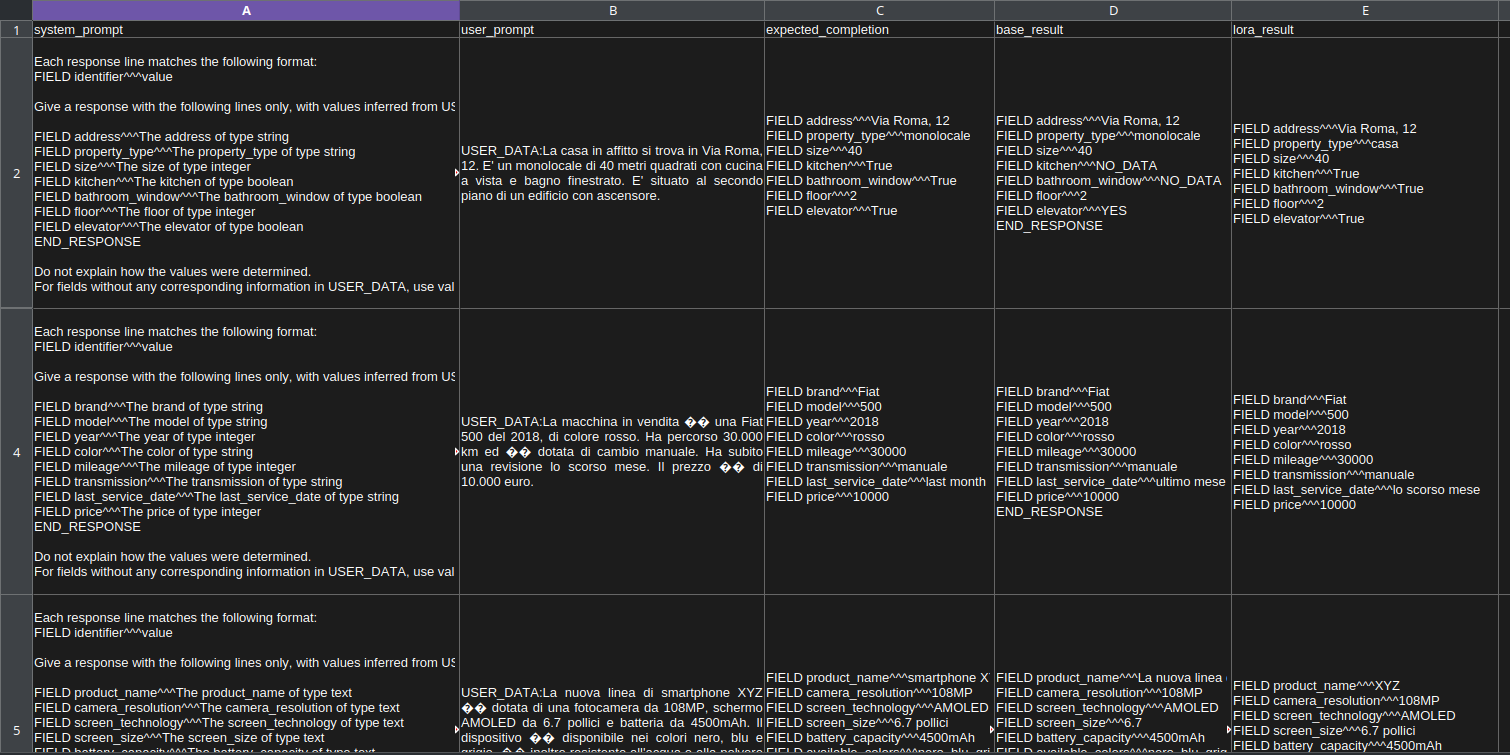
This is a simple way to evaluate the model, but generally speaking, evaluation is a complicated topic and there are many aspects to consider. There is a lot of literature on benchmarks that is worth looking into, but for a first simple evaluation of small models on specific tasks, a comparison like the one presented can be useful.