Alignment con KTO
Presentazione dell'algoritmo KTO (Kahneman-Tversky Optimization) ed esempi per creazione di dataset
Algoritmi HALO
Nell’ambito dell’alignment degli LLM, gli algoritmi di tipo HALO (Human-Aware LOss Function) svolgono un ruolo importante. La caratteristica di tali algoritmi fa sì che non bisogna definire a priori una funzione di reward, ma si può utilizzare un dataset di preferenze per istruire il modello.
In sostanza un algoritmo HALO apprende una funzione di reward basandosi su un dataset di preferenze esaminato in offline durante il training.
L’approccio è nato nell’ambito della navigazione robotica ma è stato subito esteso anche per l’alignment di LLM.
Tra i vari algoritmi di tipo HALO che sono stati creati, quello che esamino in questo post è il KTO (Kahneman‑Tversky Optimization).
KTO
L’algoritmo è descritto nel paper KTO: Model Alignment as Prospect Theoretic Optimization.
Prende spunto dalla teoria dei prospetti di Kahneman e Tversky, in particolare dal concetto di avversione alle perdite.
In ambito finanziario, per esempio, le persone hanno la tendenza a provare un dolore psicologico maggiore per una perdita, rispetto al piacere per un guadagno di pari ammontare. Questo bias influenza la nostra percezione e porta a proteggerci dalle perdite evitando rischi che, tuttavia, implicano la rinuncia a possibilità di guadagno maggiori.
Per quanto riguarda l’implementazione dell’algoritmo, KTO prevede di usare un dataset di preferenze binario (buono/cattivo) che semplifica la raccolta dei feedback, al contrario degli altri algoritmi HALO che usano coppie di preferenze.
Esempio, un classico algoritmo HALO che è il DPO (Direct Preference Optimization) richiede di avere una coppia di preferenze (chosen/rejected) per lo stesso prompt.
1
2
3
4
5
6
7
8
9
10
11
12
[
{
"prompt": "Qual è la capitale d'Italia?",
"chosen": "Roma.",
"rejected": "Milano."
},
{
"prompt": "Riassumi in una frase: 'Il sonno migliora memoria e salute'.",
"chosen": "Il sonno aiuta memoria e salute, quindi è importante dormire bene.",
"rejected": "Dormire è noioso e fa perdere tempo."
}
]
invece un prompt KTO è più semplice ed ha una sola preferenza etichettata come vero/falso:
1
2
3
4
5
6
7
8
9
10
11
12
[
{
"prompt": "Qual è la capitale d'Italia?",
"completion": "Roma.",
"label": true
},
{
"prompt": "Riassumi in una frase: 'Il sonno migliora memoria e salute'.",
"completion": "Dormire è noioso e fa perdere tempo.",
"label": false
}
]
In generale avremo un dataset composto da un certo numero di preferenze positive e negative.
L’algoritmo KTO premia le preferenze positive con un peso crescente (peso di confidenza) quando il modello è incerto nella sua risposta e penalizza le preferenze negative con maggiore forza (avversione alle perdite) quando il modello le considera probabili.
Iperparametri
Dal punto di vista operativo nel paper KTO sono descritti gli iperparametri che possono essere utilizzati per configurare l’algoritmo, rapportandone l’entità con le prove sperimentali fatte su addestramenti di Llama 3.1 8B e Qwen2.5 3B Instruct.
I valori di partenza suggeriti sono:
Learning Rate: 5e-6 se si usa un optimizer di tipo AdamW.
Epochs: 1, 2 dovrebbero essere sufficienti.
Batch Size: per un corretto funzionamento usare batch compresi tra 8 e 128.
32 potrebbe essere un buon punto di partenza.
Beta: (regolatore di stabilità), usato per il concetto di avversione al rischio, decide quanto il modello che si sta allineando deve essere penalizzato se si allontana dal modello di riferimento addestrato tramite SFT.
β basso (vicino a 0) significa che il modello è libero di allontanarsi dal riferimento, per massimizzare le ricompense.
β alto (vicino a 1) significa che il modello è penalizzato se si allontana dal riferimento, per minimizzare le perdite e garantire la stabilità, limitando potenziali miglioramenti del modello stesso.
Nel paper KTO si suggerisce un valore di 0.1.
Desiderable/Undesirable Weights: pesi usati per regolare l’avversione alle perdite, dando maggiore o minore importanza alle preferenze positive o negative.
Il rapporto tra i pesi è cruciale soprattutto in presenza di dataset sbilanciati nel numero di preferenze positive e negative.
possiamo regolare i pesi rispettando il range suggerito dalla formula mostrata nel paper:
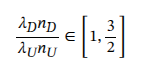
con:
nD = numero preferenze positive, nU = numero preferenze negative
λD = peso preferenze positive, λU = peso preferenze negative
per cui, se abbiamo un dataset bilanciato possiamo usare: λU = 1, λD = 1 (default)
se abbiamo un dataset sbilanciato con rapporto 1:10 (un esempio positivo ogni 10 negativi):
λD = [10, 15], λU = 1
oppure se abbiamo nD = 9000, nU = 3000 possiamo usare: λD = 1, λU = [2, 3].
Si è sperimentato che KTO riesce a gestire forti squilibri tra numeri di preferenze positive e negative, anche con molte meno preferenze positive.
Implementazione con TRL e axolotl
Per usare KTO con TRL si usano le classi KTOTrainer e KTOConfig.
Axolotl fornisce supporto per KTO (wrapper per TRL) attraverso diversi formati di dataset.
Per un formato custom del tipo:
1
2
{"system":"You are Pasquale, chatting with Lorenzo. Respond naturally in their conversational style.","prompt":"Daje giù","completion":"Non mi interessa.","label":false}
{"system":"You are Pasquale, chatting with Lorenzo. Respond naturally in their conversational style.","prompt":"Daje giù","completion":"eh :(","label":true}
possiamo usare la configurazione:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
base_model: meta-llama/Llama-3.1-8B-Instruct
rl: kto
rl_beta: 0.1 # default
kto_desirable_weight: 1.0 # puoi aumentare se hai pochi "desiderabili"
kto_undesirable_weight: 1.0 # puoi aumentare se hai pochi "indesiderabili"
remove_unused_columns: false
datasets:
- ds_type: json
data_files:
- /abs/path/dataset-kto-labeled.jsonl
split: train
type:
field_prompt: "prompt"
field_system: "system"
field_completion: "completion"
field_label: "label"
prompt_format: "{prompt}"
completion_format: "{completion}"
gradient_checkpointing: true
gradient_checkpointing_kwargs:
use_reentrant: true
Dataset per KTO
La generazione di un dataset per KTO dipende dalla situazione specifica per cui si sta allineando il modello.
Per esempio, dopo aver eseguito un SFT, potremmo generare un dataset per l’alignment con KTO, a partire dal dataset di SFT.
Le preferenze binarie positive potrebbero essere create a partire dal dataset di SFT e le preferenze negative sintetiche potrebbero essere generate per inferenza dal modello base ante SFT, magari con sampling aggressivi (parametri di temperatura alta, top-p basso etc.)
Tornando all’esempio del dataset costruito dalle chat telegram del progetto LLM “Chat Like Me”, possiamo usare diversi approcci per generare dataset di preferenze negative.
Anzitutto possiamo usare le risposte del modello fine tunato e mettere da parte quelle che non sono in linea con lo stile cercato ed usarle come esempi negativi.
Questo metodo richiede un’analisi manuale delle risposte ed è sicuramente costoso in termini di tempo e risorse. Però è ovviamente efficace per allineare il chatbot.
Tuttavia, in genere, si possono usare diversi approcci automatizzati per generare esempi negativi sintetici.
Per esempio:
Base model con sampling aggressivo: generando risposte dal modello base (ante SFT) con parametri che aumentano la variabilità delle risposte (parametri di temperatura alta, top-p basso etc.), nell’esempio si usa un tono generico/formale.
1
2
3
4
5
6
{
"prompt": "Daje giù",
"completion": "La ringrazio per il suo messaggio. Valuterò attentamente.",
"label": false
}
Shuffle/Corruzione di risposte reali: alterando le risposte (aggiunta/rimozione di parole, cambio di ordine delle parole, rimozione emoji/tono, formalizzazione forzata).
1
2
3
4
5
{
"prompt": "domani mattina devo fare la spesa",
"completion": "se vuoi ti accompagno -> con l'elicottero <-, dai!",
"label": false
}
Contaminazione con altri dataset o/e template generici/formali: usando risposte di altri interlocutori/persone prese da prompt simili, oppure frasi standard, neutrali o eccessivamente formali non in linea con lo stile cercato.
1
2
3
4
5
{
"prompt": "non posso accompagnarti, mi dispiace!",
"completion": "La ringrazio per il suo messaggio. Valuterò attentamente.",
"label": false
}
Paraphrasing negativo: parafrasando una risposta corretta,rendendola più lunga, neutra o troppo professionale.
1
2
3
4
5
{
"prompt": "ok dai",
"completion": "ahahah! -> Comprendo il tuo punto di vista e procederò di conseguenza. <-",
"label": false
}
Template contestuali (augmentation): riempiendo schemi generici con parti del prompt, mantenendo il contenuto ma perdendo lo stile cercato.
1
2
3
4
5
{
"prompt": "Su {topic} capisco la tua posizione. {conclusione neutra}.",
"completion": "La ringrazio per il suo messaggio. Valuterò attentamente.",
"label": false
}
Questi sono solo alcuni esempi, importante è adattare il dataset alle esigenze cercate.