LLM “Chat Like Me” project - Part 2 - Fine-tuning
In Part 1, we collected and prepared a dataset from Telegram chat history.
Now the idea is to fine-tune a model that can run locally on my PC with the provided dataset.
Training vs. Fine-tuning: An Important Distinction
Let’s be clear about what we’re doing here. We’re not training a large language model from scratch. That would require millions of dollars in computational resources, massive datasets, and months of training time on specialized hardware. That’s what companies like Meta, OpenAI, and Google do.
Instead, we’re fine-tuning a pre-trained model. This means taking an existing model that already understands language, grammar, and chat patterns, and then teaching it to adopt a specific conversational style.
Choosing a Base Model: Llama 3.1
For this project, I chose Meta’s Llama 3.1 8B as the base model. The Llama family of models is open-source and offers decent performance for conversational tasks, which seemed like a reasonable choice for these experiments.
The 8 billion parameters version should strike a good balance between capability and computational requirements. It’s small enough to fine-tune on consumer-grade GPUs while potentially producing high-quality, contextually appropriate responses.
Hardware Setup for Fine-tuning
When it comes to fine-tuning LLMs, you have two main options: cloud-based services or local hardware. Cloud services like Runpod, Google Colab, or Lambda Labs offer the flexibility to rent powerful GPUs by the hour, making them accessible even if you don’t own high-end hardware at reasonable cost.
For this project, I chose to use my local machine instead of cloud services. I enjoy having full control over the hardware and the freedom to experiment with different software settings and configurations. Here’s my setup:
Hardware Specifications:
- CPU: 13th Gen Intel Core i7-13700K
- RAM: 128GB DDR4
- GPU: 2x NVIDIA GeForce RTX 3090 (24GB VRAM each = 48GB total)
- OS: Linux 6.16.8 (Endeavour OS / Arch-based)
The dual RTX 3090 setup is well-suited for this 8B model. Each card has 24GB of VRAM, which is sufficient to handle an 8B parameter model with 4-bit quantization.
However, if you want to fine-tune larger models (like Llama 3.1 70B or 405B), local consumer hardware quickly becomes insufficient. For those cases, you would need to rely on cloud services like Runpod, Lambda Labs, or other providers that offer high-end datacenter GPUs (A100 80GB, H100).
Choosing a Training Framework: Axolotl
There are many frameworks available for fine-tuning LLMs. Two of the most popular are Unsloth and Axolotl.
Unsloth is known for its speed optimizations and offers more granular control over the training process with extensive customization options. However, I chose Axolotl for this project because it better suited my needs.
The primary factor was Axolotl’s multi-GPU support through DeepSpeed integration, which has been robust for a long time. In contrast, Unsloth’s multi-GPU capabilities are still in an early development stage.
Additionally, I appreciated Axolotl’s straightforward configuration approach. After setting up some additional software dependencies, Axolotl worked reliably on my dual-GPU setup without any issues.
Setting Up the Training Configuration
Axolotl uses YAML configuration files to define all training parameters. Here’s the configuration I used for this project:
Axolotl configuration file is available in the project’s GitHub repository: chat-like-me
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
base_model: NousResearch/Meta-Llama-3.1-8B
load_in_4bit: true
strict: false
chat_template: llama3
datasets:
- path: /path/to/training_data.json
type: chat_template
message_field_role: role
message_field_content: content
dataset_prepared_path: last_run_prepared
val_set_size: 0.005
output_dir: ./outputs/lora-out
sequence_len: 4096
sample_packing: true
eval_sample_packing: false
pad_to_sequence_len: true
adapter: qlora
lora_r: 64
lora_alpha: 32
lora_dropout: 0.05
lora_target_linear: true
lora_modules_to_save:
- embed_tokens
- lm_head
peft_use_dora: true
wandb_project: chat-like-me
wandb_entity:
wandb_watch:
wandb_name:
wandb_log_model:
gradient_accumulation_steps: 2
micro_batch_size: 1
num_epochs: 4
optimizer: adamw_bnb_8bit
lr_scheduler: cosine
learning_rate: 0.0002
train_on_inputs: false
bf16: true
tf32: true
gradient_checkpointing: true
logging_steps: 1
flash_attention: true
warmup_ratio: 0.1
evals_per_epoch: 1
saves_per_epoch: 1
weight_decay: 0.0
deepspeed: /path/to/deepspeed_configs/zero2.json
special_tokens:
pad_token: "<|finetune_right_pad_id|>"
eos_token: "<|eot_id|>"
The configuration file is organized into several logical sections, each controlling different aspects of the fine tuning process.
Let’s now explore the configuration sections in more detail where necessary.
Note: The following sections are quite technical. If you’re not interested in the configuration details, you can skip ahead to the Fine Tuning Process section.
Base Model and Quantization
1
2
3
base_model: NousResearch/Meta-Llama-3.1-8B
load_in_4bit: true
strict: false
The model is downloaded from Hugging Face and quantized to 4-bit precision, reducing memory usage by ~75% compared to full precision. This 4-bit quantization is the core of the QLoRA technique.
Dataset and Chat Template Configuration
1
2
3
4
5
6
7
8
chat_template: llama3
datasets:
- path: /path/to/training_data.json
type: chat_template
message_field_role: role
message_field_content: content
dataset_prepared_path: last_run_prepared
val_set_size: 0.005
The dataset is configured to use Llama 3’s chat format with the OpenAI chat-template structure (system/user/assistant roles). The prepared JSONL file from Part 1 is split into 99.5% training and 0.5% validation data to monitor overfitting during training.
Sequence Length and Packing
1
2
3
4
sequence_len: 4096
sample_packing: true
eval_sample_packing: false
pad_to_sequence_len: true
Conversations are converted into sequences of tokens to be fed into the model during training. They are limited to 4096 tokens. The sample_packing feature combines multiple short conversations into single training batches.
LoRA/QLoRA Configuration
1
2
3
4
5
6
7
8
9
adapter: qlora
lora_r: 64
lora_alpha: 32
lora_dropout: 0.05
lora_target_linear: true
lora_modules_to_save:
- embed_tokens
- lm_head
peft_use_dora: true
LoRA works by adding trainable low-rank matrices to the attention layers of the transformer, allowing efficient adaptation without modifying the original model weights.
adapter: qlora: Uses QLoRA (Quantized LoRA) technique, which applies quantization to reduce memory usage and speed up training.lora_r: 64: The rank of the LoRA adapter matrices. Higher values (like 64) give the model more capacity to learn patterns but require more memory. Typical values range from 8 to 128lora_alpha: 32: Scaling factor that controls how much the adapter influences the base model. The ratiolora_alpha/lora_rdetermines the learning strengthlora_dropout: 0.05: Applies 5% dropout(1) to prevent overfitting(2) in the adapter layerslora_target_linear: true: Applies LoRA to all linear layers in the transformer blocks (attention(3) and feed-forward)lora_modules_to_save: In addition to LoRA adapters, these modules are fully fine-tuned. The embedding (embed_tokens) and output (lm_head) layers often benefit from full fine-tuning, especially when working with specific vocabulary or domainspeft_use_dora: true: Enables DoRA (Weight-Decomposed Low-Rank Adaptation), a recent improvement over standard LoRA that separates magnitude and direction updates for better performance
The lora_target_linear: true setting ensures that LoRA adapters are automatically applied to all linear layers in the transformer architecture. For Llama 3.1, Axolotl automatically detects and targets the following modules: q_proj, k_proj, v_proj, o_proj (attention layers), and gate_proj, up_proj, down_proj (feed-forward layers).
(1) dropout is a regularization technique that randomly “turns off” a subset of neurons during training, helping to prevent overfitting by forcing the network to learn more robust features.
(2) overfitting occurs when a model adapts too closely to the details and noise in the training data, compromising its ability to generalize. The model learns not only the underlying patterns but also random fluctuations and anomalies specific to the training set, resulting in excellent performance on training data but poor performance on new, unseen data.
(3) attention is a mechanism in neural networks that allows the model to focus on relevant parts of the input data. It is used in transformer models to process sequences of tokens in parallel, allowing the model to learn relationships between words and phrases in a more efficient way.
Training Hyperparameters
1
2
3
4
5
6
gradient_accumulation_steps: 2
micro_batch_size: 1
num_epochs: 4
optimizer: adamw_bnb_8bit
lr_scheduler: cosine
learning_rate: 0.0002
gradient_accumulation_steps: 2: Accumulates gradients(4) over 2 forward passes before updating weights. This simulates a larger batch size (effective batch size = micro_batch_size × gradient_accumulation_steps × num_gpus = 1 × 2 × 2 = 4) without requiring more memorymicro_batch_size: 1: Processes one conversation at a time per GPU. With sample packing enabled, this could contain multiple conversations packed into 4096 tokensnum_epochs: 4: Iterates through the entire dataset 4 times. More epochs can lead to better adaptation but risk overfittingoptimizer: adamw_bnb_8bit: Uses 8-bit AdamW optimizer (from bitsandbytes library) for memory efficiencylr_scheduler: cosine: scheduler(5) setting: learning rate(5) follows a cosine curve, starting at the specified rate and gradually decreasing to near zerolearning_rate: 0.0002: Starting learning rate(6). This is relatively standard for LoRA fine-tuning
(4) gradient accumulation is a technique to avoid running out of VRAM during training. Normally, the model weights are updated after every batch using the calculated gradients. With gradient accumulation, instead of updating immediately, the gradients are accumulated (summed) over multiple batches. The model weights are only updated after a specified number of iterations. This allows training with larger effective batch sizes without requiring additional memory.
(5) A scheduler dynamically adjusts the learning rate during training according to a predefined schedule. The cosine scheduler starts at the specified rate and gradually decreases following a cosine curve, helping achieve better convergence and avoiding issues like overshooting or slow convergence.
(6) Learning rate is a hyperparameter that controls how quickly the model learns. Finding the correct value can be difficult
Training Efficiency Settings
1
2
3
4
5
6
7
8
9
10
train_on_inputs: false
bf16: true
tf32: true
gradient_checkpointing: true
logging_steps: 1
flash_attention: true
warmup_ratio: 0.1
evals_per_epoch: 1
saves_per_epoch: 1
weight_decay: 0.0
train_on_inputs: false: Only computes loss(6) on assistant responses, not on system prompts or user messages. This focuses learning on your conversational stylebf16: true: Uses bfloat16 precision for training, which balances memory efficiency with numerical stabilitytf32: true: Enables TensorFloat-32 on compatible GPUs (like RTX 3090) for faster matrix operationsgradient_checkpointing: true: Trades computation for memory by recomputing activations during backward pass instead of storing them all. Essential for training larger modelslogging_steps: 1: Logs training metrics every step (useful for monitoring but can slow things down slightly)flash_attention: true: Uses Flash Attention 2, a highly optimized attention implementation that significantly speeds up trainingwarmup_ratio: 0.1: Gradually increases learning rate from 0 to the target over the first 10% of training steps to prevent instabilityevals_per_epoch: 1: Evaluates on validation set once per epochsaves_per_epoch: 1: Saves a checkpoint once per epochweight_decay: 0.0: No weight decay(7) regularization. LoRA’s low rank already provides implicit regularization
(6) loss is a measure of how well the model is performing. It is used to guide the training process and improve the model’s performance.
(7) weight decay is a technique to prevent overfitting by limiting the values that weights can assume. It adds a penalty proportional to the sum of squared weights to the loss function, pushing weights toward smaller values and stabilizing the model.
DeepSpeed Configuration
1
deepspeed: /path/to/deepspeed_configs/zero2.json
DeepSpeed is a distributed training library that enables efficient multi-GPU training. The ZeRO (Zero Redundancy Optimizer) technique comes in three stages:
- ZeRO-1: Partitions optimizer states across GPUs.
- ZeRO-2: Partitions both optimizer states and gradients, I use this one here.
- ZeRO-3: Partitions model parameters, optimizer states, and gradients. Maximum memory savings but requires more inter-GPU communication.
In my setup, I used an ADAM(7) optimizer (the algorithm that updates model weights during training based on calculated gradients).
ZeRO-1 only partitions ADAM optimizer states across GPUs, but in my case this wasn’t enough to avoid memory saturation. Switching to ZeRO-2 resolved the issue because it partitions both ADAM optimizer states and gradients across the two RTX 3090s.
(7) ADAM is an optimizer that maintains two inner momentum states for each model parameter: a moving average of gradients (first moment) and a moving average of squared gradients (second moment). This optimizer state typically requires about 8 bytes per model weight, which adds substantial memory overhead even with 8-bit quantization.
Special Tokens
1
2
3
special_tokens:
pad_token: "<|finetune_right_pad_id|>"
eos_token: "<|eot_id|>"
Special tokens are used to structure the conversation format. The pad_token fills sequences to uniform length, while the eos_token (end-of-sequence) marks the end of each turn in Llama 3.1’s chat format, signaling when the assistant has finished its response.
Weights & Biases Integration
1
2
3
4
5
wandb_project: chat-like-me
wandb_entity:
wandb_watch:
wandb_name:
wandb_log_model:
These settings configure Weights & Biases, a tool for tracking and logging the training process, including metrics like loss, learning rate, and GPU utilization.
Fine Tuning Process
Once the configuration is set, starting the fine tuning with:
1
axolotl train config.yml
The fine tuning process typically takes several hours on my machine, generally depending on hardware and dataset size. During fine tuning, you can monitor progress in real-time through wandb, which provides comprehensive telemetry and visualization of the fine tuning process.
For example, you can track the loss function on both training and evaluation data. The training loss typically decreases steadily as the model learns, while the evaluation loss should also decrease initially. However, if the evaluation loss starts to increase while training loss continues to drop, this indicates the beginning of overfitting—the model is memorizing the training data rather than learning generalizable patterns.
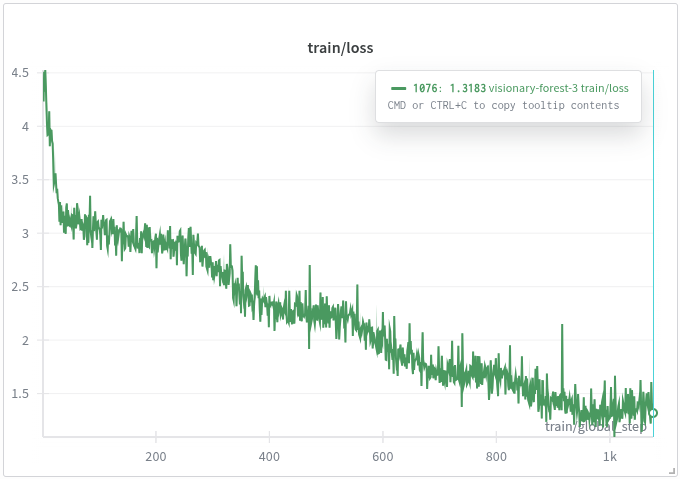 Training loss decreases steadily throughout training
Training loss decreases steadily throughout training
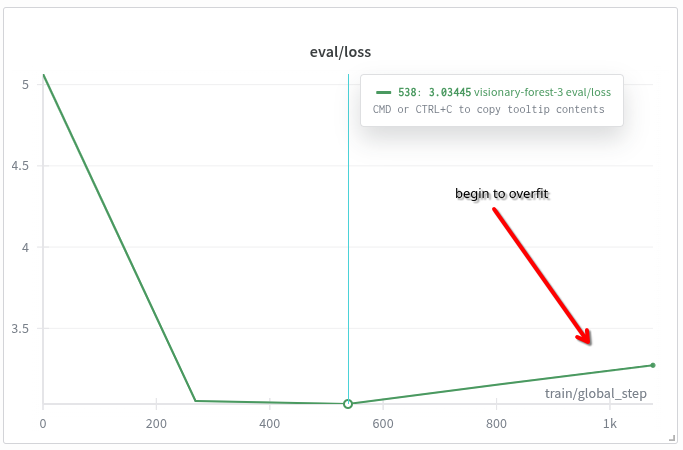 Evaluation loss starts to increase around step 600, indicating the beginning of overfitting
Evaluation loss starts to increase around step 600, indicating the beginning of overfitting
Note on Overfitting: The evaluation loss shows early signs of overfitting, which suggests stopping the fine tuning early at 3 epochs. However, the training loss remains reasonable at 4 epochs, so I decided to continue fine tuning for the full 4 epochs.
Next Steps: Model Inference
Once the fine-tuning process is complete, the trained model adapters (LoRA weights) are saved in the output directory. Now comes the exciting part 😃 testing whether the model has actually learned your conversational style.
You can now query the model for inference by loading the base model along with the fine-tuned LoRA adapters. There are two approaches: either merge the LoRA weights directly into the base model for more efficient production deployments, or load the adapters dynamically at runtime for greater flexibility. For this project, I chose to load the adapters dynamically, as it allows experimenting with different fine-tuned versions without rebuilding the entire model.
In the next part of this series, we’ll explore how to load and use the fine-tuned model for inference, and create a chatbot interface to interact with the model.