LLM “Chat Like Me” project - Part 1 - Dataset Preparation
This project is born out of curiosity and a desire to learn how to fine-tune large language models hands-on. It’s also a fun experiment to see if I can create an AI that replicates my conversational style :) when I’m chatting with friends, colleagues, etc.
The goal is to fine-tune Llama 3.1 8B using my personal and group chat history from Telegram. By leveraging my actual conversations as training data, I’ll capture the nuances, vocabulary, and patterns that make up my unique communication style. Through this process, I’ll explore the entire pipeline of model training, from data collection to evaluation, while creating an AI finetuned model that can “chat like me.”
Why Telegram?
I chose to use Telegram as my data source for several reasons. First and foremost, I use it frequently from many years for both personal conversations and group chats, which means I have a substantial amount of chat history to work with.
I find Telegram superior to alternatives like WhatsApp, particularly for this kind of project. Telegram offers a built-in export feature that makes it easy to download your entire chat history in structured formats like JSON, which is perfect for data processing too. The platform is also more developer-friendly, with better tools and APIs for data handling, bots development and so on.
Data Collection
The data collection process will involve extracting chat history from both personal and group conversations on Telegram.
Telegram Desktop provides a built-in feature to export all your chat history at once, which you’ll use to collect your training data.
How to Export All Chats from Telegram
Following steps from this article you can export all your chat history (personal and group chats) in JSON format.
Open telegram desktop and go to Settings -> Advanced -> “Export Telegram Data”
In the export settings window a reasonable decision can be to check “Personal chats” and “Private groups” and uncheck “Photos/Videos” and “Voice messages” to not include possibly misleading data or files like photos, videos, voice messages, etc.
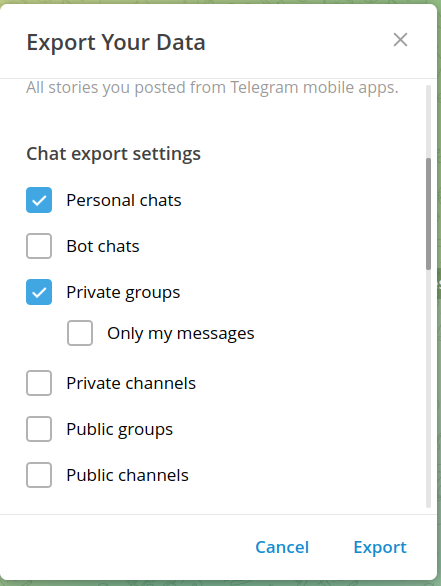
Remember: The goal is to train a model that can chat like yourself with friends, colleagues, etc. so you need to include that chat history only!
Understanding the Exported JSON Structure
Once the export is complete, you’ll have a large JSON file (potentially hundreds of megabytes) containing all your chat history. The structure looks like this:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
{
"about": "Here is the data you requested...",
"chats": {
"about": "This page lists all chats from this export.",
"list": [
{
"name": "Weekend Plans Group",
"type": "private_group",
"id": 123456789,
"messages": [
{
"id": 1001,
"type": "service",
"date": "2023-01-15T14:30:00",
"date_unixtime": "1673792400",
"actor": "User123",
"actor_id": "user987654321",
"action": "create_group",
"title": "Weekend Plans Group",
"members": [
"User123",
"Alice",
"Bob"
],
"text": "",
"text_entities": []
},
{
"id": 1002,
"type": "message",
"date": "2023-01-15T14:31:00",
"date_unixtime": "1673792460",
"from": "User123",
"from_id": "user987654321",
"text": "Hey everyone!",
"text_entities": [
{
"type": "plain",
"text": "Hey everyone!"
}
]
},
{
"id": 1003,
"type": "message",
"date": "2023-01-15T14:32:00",
"date_unixtime": "1673792520",
"from": "Alice",
"from_id": "user111222333",
"text": "Hi! What's up?",
"text_entities": [
{
"type": "plain",
"text": "Hi! What's up?"
}
]
}
]
},
{
"name": "John Doe",
"type": "personal_chat",
"id": 987654321,
"messages": [
{
"id": 2001,
"type": "message",
"date": "2023-02-20T10:15:00",
"date_unixtime": "1676887500",
"from": "User123",
"from_id": "user987654321",
"text": "Did you finish the project?",
"text_entities": [
{
"type": "plain",
"text": "Did you finish the project?"
}
]
},
{
"id": 2002,
"type": "message",
"date": "2023-02-20T10:16:00",
"date_unixtime": "1676887560",
"from": "John Doe",
"from_id": "user444555666",
"text": "Almost done, just some final touches",
"text_entities": [
{
"type": "plain",
"text": "Almost done, just some final touches"
}
]
}
]
}
]
}
}
This structured format makes it relatively straightforward to parse and extract the conversation data you need for training.
Data Preparation and Chat Templates
Once you have the raw JSON export, you need to transform it into a training-ready dataset. The real work begins here because there are several challenges to overcome and you need to be careful with the data quality.
Data quality is crucial! It directly impacts how well the model learns your conversational style.
The transformation process requires three essential steps, all of which are necessary:
Cleaning: Filter out group chats (unless you want multiple personalities), infrequent contacts, automated messages, and non-text content.
Structuring: When you chat with someone, there’s typically a rapid back-and-forth exchange about a specific topic. Then hours might pass before you chat again about something completely different. To maintain logical coherence in the training data, we need to separate these distinct conversation segments.
A good approach is to group messages that occur within 5 minutes (turn window) or more time apart of each other as part of the same conversational topic, while treating gaps longer than an hour as natural breaks between different discussions. This will help the model learns to respond within context rather than mixing unrelated topics.
Formatting: The dataset will be formatted using OpenAI’s chat template, which is a widely-adopted standard format for conversational AI.
Each conversation is structured as an array of messages with role assignments: system for context, user for the other person’s messages, and assistant for your messages. Also include the name field to preserve who said what.
Implementation: From exported telegram JSON to dataset
Now let’s dive into how you can implement this transformation process. The result.json file exported from Telegram is massive (several hundred megabytes of years of chats), especially if you decided to export all your chats at once. Navigating through this data to find specific conversations and process them systematically was challenging, so I created a utility parse_chats.py to parse the JSON and extract to a list the chat names, their types (personal, groups, private, public etc.) and their IDs.
All the scripts mentioned in this article are available in the project’s GitHub repository: chat-like-me
1
2
3
4
5
6
7
8
9
10
11
12
python parse_chats.py --save-all --input result.json
example output:
--------------------------------------------------------------------------------
Name Type ID
--------------------------------------------------------------------------------
Giuliana personal_chat 164456975
Barbara personal_chat 1141451558
Marco personal_chat 626965680
Dove per la svolta private_group 1437880907
Now that you can easily identify chats of interest, the next step is to extract them into separate JSON files for easier processing. You can use another script extract_conversation.py to do this:
1
2
3
4
5
6
7
8
9
python extract_conversation.py result.json --id 460911860 --output out-specific-id.json
example output:
Found conversation:
ID: 460911860
Name: Lorenzo
Type: personal_chat
Messages: 379089
This extracts a single conversation (identified by its ID) from the massive result.json into a dedicated file. This makes it much easier to handle each conversation separately and individuate the data for the training process.
Once all relevant conversations have been identified and extracted, you can transform them into the chat template format required for training. This is where you apply the cleaning, structuring, and formatting steps described earlier to create the final training dataset.
I created also a comprehensive script prepare_training_data.py that handles the entire transformation pipeline:
1
python prepare_training_data.py result.json --output training_data.jsonl
The script automatically performs all three transformation steps (Cleaning, Structuring, Formatting) and offers several configurable parameters:
--min-messages(default: 20): Filters out contacts with too few messages--turn-window(default: 5): Time window in minutes to group consecutive messages from the same person as a single turn--conversation-gap(default: 60): Time gap in minutes that separates distinct conversations--your-name(default: Pasquale): Your name in the chats, used to identify which messages are yours (assistant role)--include-groups: By default, only personal chats are included. Use this flag to also include group conversations
default values working well for me, but you can adjust them to your needs.
Example usage with custom parameters:
1
2
3
4
5
6
7
8
9
# Process with stricter filtering (50+ messages) and wider time windows
python prepare_training_data.py result.json \
--min-messages 50 \
--turn-window 10 \
--conversation-gap 120 \
--your-name "Pasquale"
# Include group chats as well
python prepare_training_data.py result.json --include-groups
The script outputs a JSONL file (JSON Lines format) where each line is a complete conversation in the OpenAI chat template format.
Example of a formatted complete conversation as part of the dataset:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
{
"messages": [
{
"role": "system",
"content": "You are Pasquale, chatting with Lorenzo. Respond naturally in their conversational style."
},
{
"role": "assistant",
"name": "Pasquale",
"content": "sto ventaccio malefico mi ha rotto la persiana ed ho dovuto legarla era aperta...col vento si è chiusa di colpo e SBAM! per XXX"
},
{
"role": "user",
"name": "Lorenzo",
"content": "Daje giù"
},
{
"role": "assistant",
"name": "Pasquale",
"content": "eh :("
},
{
"role": "assistant",
"name": "Pasquale",
"content": "C'è gia a chi è andata peggio col vento…"
},
{
"role": "user",
"name": "Lorenzo",
"content": "Esatto"
}
]
}
The system message “You are Pasquale, chatting with Lorenzo…” instructs the model to act as Pasquale when chatting with Lorenzo. During training, this helps the model learn to associate this context with Pasquale’s conversational style when chatting with Lorenzo.
So, when the trained model is later used, setting the same system prompt will trigger the model to respond in Pasquale’s style when specific Lorenzo user asks questions.
It’s like giving the model its identity and role for the conversation.
Now you are ready to fine-tune the model because you have a valid dataset.
Continue to Part 2: Fine-tuning the Model with the Dataset